Natural Language Processing

How it started
I was listening to a UK-based politics and culture podcast when a short reference to a purportedly known fact caught my attention.
The podcast host asserted that one can identify the political bias of an author by his or her word choices and how frequently they use French-origin words versus German-origin words, with French on the political "Left" and German on the political "Right."
I had been looking for a project to start working with in familiarizing myself with Natural Language Processing (NLP) methods and decided to try and test whether the podcast host was correct or not.
Proposed initial data:
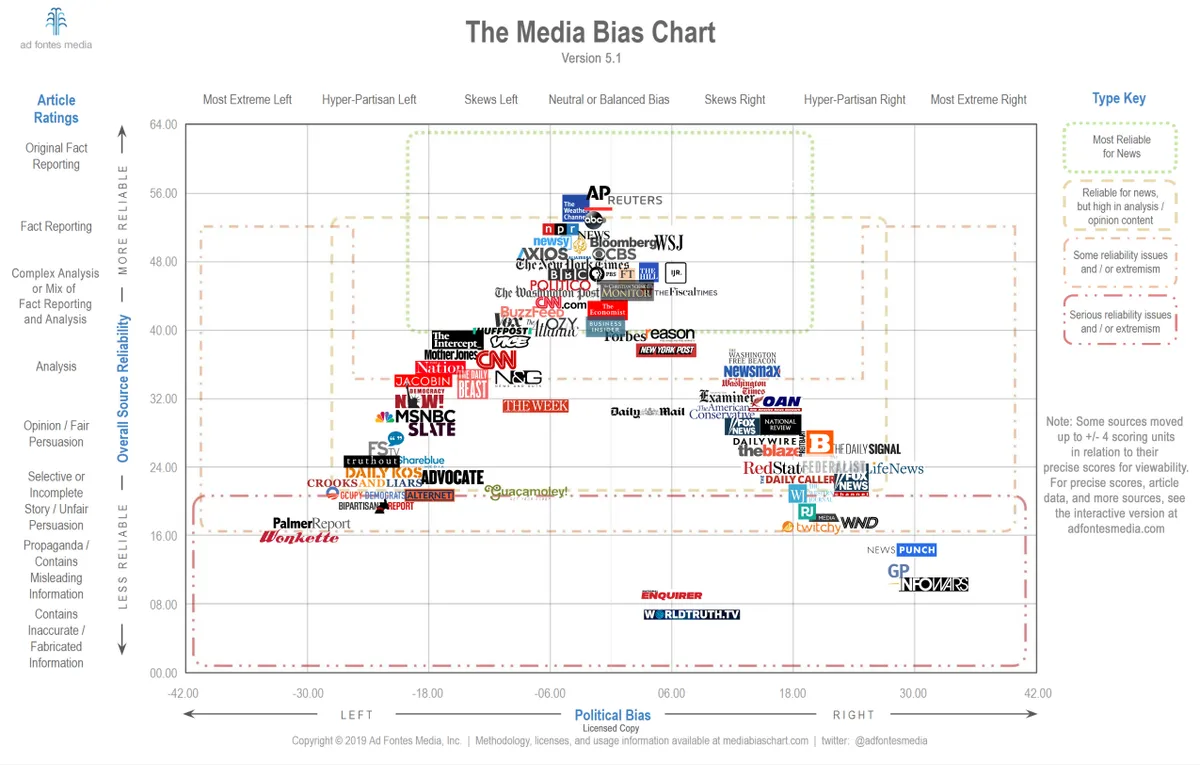
10 articles each from 2 news outlets declared political left and right using an accepted media bias chart
Proposed steps:
- Using the body text of each article, segregate each word or symbol.
- Lemmatize (normalize to base) words to isolate word roots.
- Create unique-item columns for each.
- Describe characteristics that differ between outlets (% and number of words used, symbols used, etc.).
- Describe lemmatized word characteristics (% and number of repeated words, % and number of words by parts of speech).
- Screen lemmatized words based on word root origin.
- Describe root word characteristics (% and number of word origins).
- Compare against media bias chart.
- Expand to include outlets in intermediate categories and compare against media bias chart. (time dependent)
- Expand number of articles per outlet and compare against previous results looking at stability of findings. (time dependent)
My planned deliverables were:
- All of the original, format unchanged, articles used
- A comma-separated values (csv) file with articles each taking one row and unique words, punctuation, diacritical marks, and wordcount enumerated by label
- A csv file containing metadata for each of the articles including UniqueKey, Title, AuthorName, PublisherName, DatePublished, and GuidLink
- A lossy csv file with punctuation and diacritical marks each aggregated under their respective data labels in columns
- A lossy csv file with words lemmatized to their normalized roots
- A csv with the above data, but with data labels appended with root word origin language
- A report outlining interesting features found when comparing the articles, including an anlysis of the likelihood of being able to use root language of words to predict political bias of the outlet
How it went
In Progress...
Current status
In Progress...
Conclusions
In Progress...
Referenced materials: